Maintenance
Most maintenance tasks in Contao are automated so that you can concentrate on your real work. Sometimes, however, it might be necessary to manually start the system maintenance tasks that are otherwise performed automatically.
Maintenance mode
This feature allows you to put the Contao instance into a “maintenance mode”. While this mode is active, the front end is not reachable for regular visitors. Instead an appropriate message is shown. The back end is accessible as usual, logged in back end users can bypass the maintenance mode using the front end preview.
This mode is useful, if more in depth work needs to be done in the back end, the effects of which should not be immediately visible in the front end.
The maintenance mode has been rewritten for Contao version 4.13. Via the command line, the complete Contao installation (back- and front end) can be put into maintenance mode. This feature is very useful if you want to update your system.
Furthermore you have the possibility to set the front end for each website root into maintenance mode.
Crawler
Pages are automatically indexed when you access them in the front end (unless you are logged into the back end at the same time), so you don’t normally have to worry about the search index. However, if you have updated many pages at once, it is more convenient to rebuild the search index manually than to call up all changed pages one by one in the browser.
The crawler can also check for broken links, when enabled.
In versions prior to Contao 4.9 this section is called Rebuild search index. The feature of being able to check for broken links is not available there.
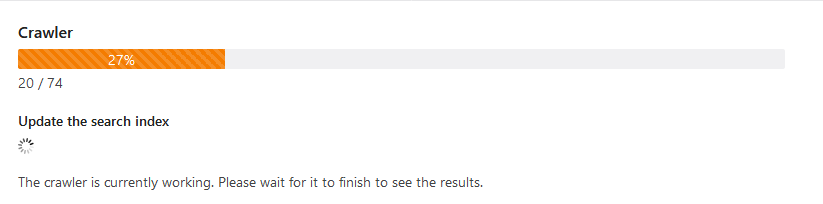
This feature is available in Contao 4.9 and later.
The crawler can also be executed directly from the command line:
$ vendor/bin/contao-console contao:crawl
However, since there is no HTTP request context available on the console, a domain must be defined. For this reason you should always define the domain in the website root settings, even if you only use one domain in your Contao instance. Alternatively you can define the default domain for the console via configuration parameters:
# config/parameters.yml
parameters:
router.request_context.host: 'example.org'
router.request_context.scheme: 'https'
You can find more information in the Symfony Routing Documentation.
Indexing protected pages
To allow the search of protected pages, you must first enable this feature in the back end settings. Use this feature very carefully and always exclude personalized pages from the search!
Since Contao 4.9 this is enabled in the application configuration:
# config/config.yml
contao:
search:
# Enable indexing of protected pages.
index_protected: true
Then create a new front end user and allow them to access the protected pages to be indexed.
Later during the search, the protected pages will of course only appear in the results if the registered front end user is allowed to access them.
Speeding up the process
The duration of the crawl process depends primarily on two factors:
- the number of pages being crawled
- the number of concurrent requests that the server can serve
Reducing the number of crawled pages
The former can be influenced, for example, by excluding URLs that are not relevant from the crawl process. You can easily find out exactly which URLs are crawled via the debug log. This can be downloaded directly in the back end while the crawl process is running. On the command line you can activate the debug log as follows:
$ vendor/bin/contao-console contao:crawl --enable-debug-csv
You will then find the log as crawl_debug_log.csv in the main directory of your Contao project. You could change the path
with --debug-csv-path if desired.
There are several ways to exclude unwanted pages from the crawl process:
-
completely exclude certain pages from crawlers via
robots.txt.The configuration takes place in the root page and follows [a standard][Google_Robots_Txt], with which you can also influence the Contao crawler. If you want to restrict certain instructions to the Contao crawler only, you can do so using
User-Agent: contao/crawler. -
exclude certain links completely from all crawl activities.
The crawler that Contao uses is called “Escargot” and accordingly you can exclude links from any crawl activity with
<a href="..." data-escargot-ignore>...</a>. If Escargot finds these links, it will always ignore them. -
exclude certain links from the search index subscriber only.
If you want a link to be observed by other subscribers but excluded from the search index subscriber, you can do this with
<a href="..." data-skip-search-index>...</a>.
It also depends on how deep the crawler should search for further URLs. The first level is the root page,
e.g. https://example.com. The second level is all pages found on https://example.com and so on. The higher the
depth value, the more links can be found and the longer the crawl process takes. You can control the depth on the
command line using the --max-depth argument. In the back end, the depth is set to 10.
since 5.3 From Contao 5.3 you can also select the depth in the back end.
Adjust the number of concurrent requests
You can also increase the number of concurrent requests. However, you must then make sure that you do not overload the server.
On the command line, you can use the --concurrency option (or the -c shortcut). In the back end the concurrency is
set to 5.
since 5.3 From Contao 5.3 you can set this value via the config.yml:
# config/config.yml
contao:
backend:
crawl_concurrency: 10
If you are wondering why it is configurable but not selectable in the back end: This value never changes. The process should never take longer - i.e. a lower concurrency - and the maximum number depends on what your server can take. This only ever changes if you provide more or fewer resources.
Basic Authentication
Before a website is published it will often be protected via “Basic Authentication” on the live or staging environment. In order for the
crawler to be able to still access the site in this case the username and password needs to be defined in the configuration. The value
of this configuration option must follow the format username:password:
# config/config.yaml
contao:
crawl:
default_http_client_options:
auth_basic: 'username:password'
You can find more configuration options for the HTTP client of the crawler in the Symfony documentation.
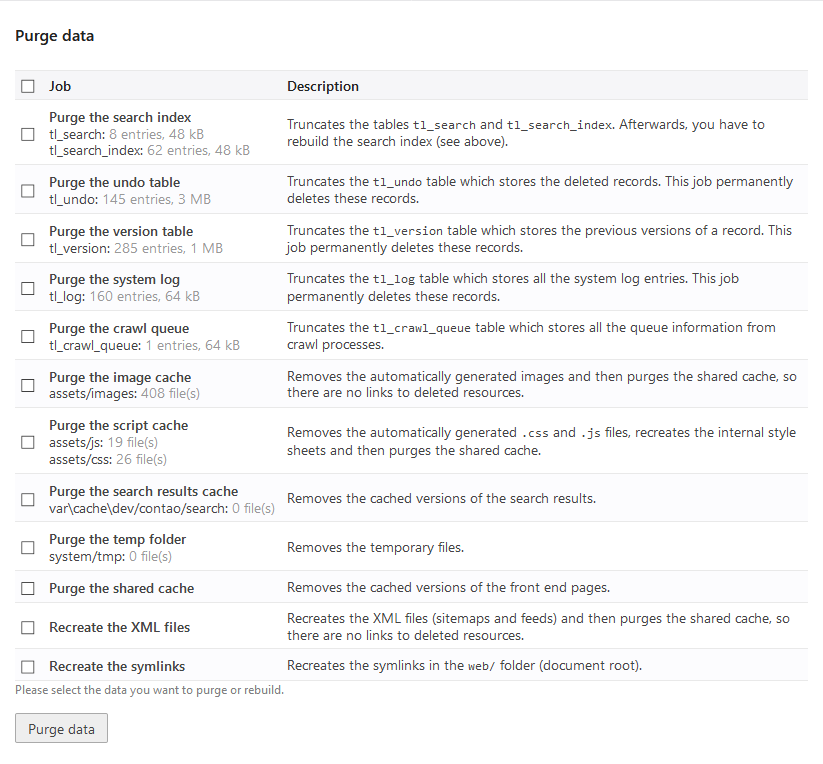
Purge data
In addition to the user-generated content, Contao stores various system data that is used the search or for restoring deleted records or previous versions. You can manually clean this data, for example to remove old thumbnails or to update the XML sitemaps after a change in the page structure.